I’ve written a lot of program code. I’ve written complete programs. I’ve written code only to throw it away. I’ve taken over projects where my recommendation was to start over – the code was that bad. This has led me to ponder…
What makes code bad or good.
There’s no pat answer. Software development is both an art and a science, and anyone who tries to sway you to one camp over the other is either an artist or a scientist.
I’m coming up on the 3 year mark on a project that has grown and had tons of features added to it. This means this topic has been on my mind a lot as I’ve been pondering the science of chaos management since changing software is nothing but chaos.
I’d like to present three practices that have helped me over the last decade, and more specifically over the last three years to keep chaos damped – manageable. These are not the only practices that will help manage changing software requirements, but I believe that they are very implementable and will give measurable results.
You may agree or disagree with me – I welcome all levelheaded comments – if you’re here to pick a fight, your comment will be deleted without remorse.
I use an acronym for these 3 ideas: PIE.
Positive Comparison Logic
For the love of all that is good in this world, please do not use negative logic names for functions that return boolean values. Consider the following two examples:
Good Example
<?php
if ( isValid() )
{
// do amazing things here
}
Bad Example
<?php
if ( ! isInvalid() == false )
{
// do something here that may or may not actually be needed...
}
Which would you rather maintain? The first example can be understood with a literal glance.
Inclusive queries
Include more fields and tables in your queries. Reduce trips to db, reduce maintenance later (no need to go back and edit queries later). If you really need to optimize a query, you can do so after initial development is done. The development process is not the time for pinching performance pennies – make your life easier, make the life of template developers easier: make more, not less data available in result sets. At the very least, give an option to do a low/full detail query as in the following example.
Example using tgsf’s query class
class someModel
{
public function fetch( $record_id, $fullDetail = false )
{
$q = query::factory()
->select()
->from( 'txn' )
->join( 'account', 'account_id = txn_account_id' )
->join( 'bank_account', 'bank_account_id = txn_bank_account_id' )
->where( 'txn_id = :txn_id' )
->bindValue( 'txn_id', $txn_id, ptINT );
if ( $fullDetail )
{
$q->join( 'entity', 'account_entity_id = entity_id' );
$q->join( 'login', 'entity_login_id = login_id' );
$q->join( 'account_type', 'account_type_id = account_account_type_id' );
$q->join( 'login_related', 'txn_login_related_id=login_related_id' );
$q->join( 'cost_table', 'login_related_cost_table_id=cost_table_id' );
}
return $q
->exec()
->fetch_ds();
}
}
Bonus tip Call functions with boolean arguments with the var name embedded in your call. This creates self-documenting code
$model = new someModel();
$model->fetch( 123, $fullDetail = true );
The query generated by the example code
SELECT * FROM txn
LEFT OUTER JOIN account ON ( account_id = txn_account_id )
LEFT OUTER JOIN bank_account ON ( bank_account_id = txn_bank_account_id )
LEFT OUTER JOIN entity ON ( account_entity_id = entity_id )
LEFT OUTER JOIN login ON ( entity_login_id = login_id )
LEFT OUTER JOIN account_type ON ( account_type_id = account_account_type_id )
LEFT OUTER JOIN login_related ON ( txn_login_related_id=login_related_id )
LEFT OUTER JOIN cost_table ON ( login_related_cost_table_id=cost_table_id )
WHERE 1=1 AND txn_id = :txn_id
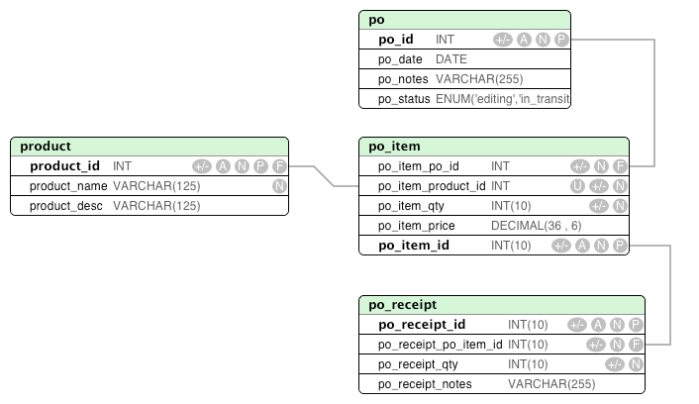
Explicit field names
This is accomplished by a structured naming approach to fields. What is the point of having 50 tables all with a field named ‘id’? At some point you’ll be aliasing or renaming that field in the application layer – all over the place. Again, what’s the point?
I’ve been using, and will use until I die, the following methodology of database structure.
- Descriptive table names. The shorter the better – make it the best but shortest name you can, but do not abbreviate unless it’s a generally accepted abbreviation in the general population of non-developers. eg: PO for purchase order, TXN for transaction, etc.
- Descriptive field names. Same logic, but make sure you can tell what the field is used for.
- Field names will be prefixed with the table name. This means that in the user table, the primary key might be: user_id. other fields: user_username, user_email, etc.
- If you do decide to do this you have to always abide by it or you’ll hate it. If you have to look up how/if you abbreviated the table name prefix on the fields of different tables you’ll hate it. Doing so is a huge mistake.
In conclusion
I’ve been using these approaches successfully since 2009 – many many changes later have proven the last 2 to be the most valuable – saving me tons of time, making it easy to write queries and work with the database. Other developers who have worked on the project have commented how they like the database structure and how it “just makes sense.”
I’d like to hear your thoughts on these approaches – if you use them, if you hate them (please tell me why).