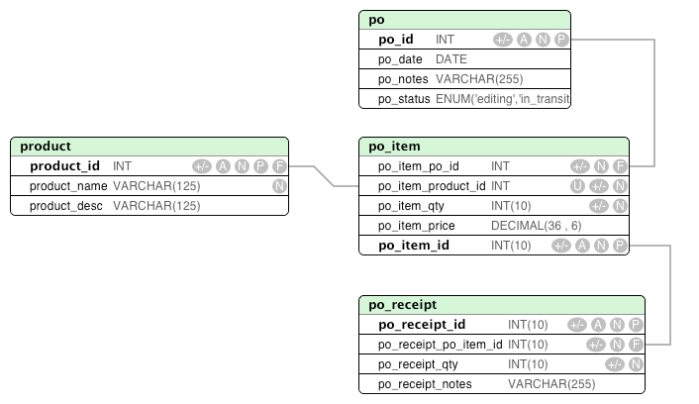
I’m adding functionality to a mature web application and need to add a field to a database table. I started mentally walking the path of the change and what all it touches and the required testing and review that would ensue and it’s mildly daunting.
Then a voice in my head said, “immutability.”
The field I would add is not necessarily a record field – it’s not data, it’s relationship. Is “relationship” data?
Instead of adding a field and reviewing and refactoring everywhere the model is used, I can simply add a relationship table, create a model and use it when needed.
Slightly more code, way less review. But I don’t know if it’s a good approach, or if anyone else has tried this, so I’m documenting this online and asking for feedback.
Do you have an opinion about this?